Overview
DeepCausality is a hyper-geometric computational causality library that enables fast and deterministic context-aware causal reasoning. Unique to DeepCausality is its ability to contextualize causal models, allowing causal reasoning over data from multiple external sources aggregated into one context. Beyond that, DeepCausality contributes several novel concepts to computational causality:
- Context
- Relations between data
- Conceptualization of time, space, and spacetime
- Structural conceptualization of causation
- Transparent composability
- Non-Euclidian data representation
Context
Numerous challenges are involved in modelling contexts suitable for general application in machine learning:
- Context changes over time.
- A change of context may happen.
- Multiple contexts may apply to a model, too.
The first challenge refers to the fact that, as time progresses, so does the change of the content embedded in a context. For example, when a car starts driving, other vehicles and pedestrians enter, move through, and leave the sight of view of the driver. In the case of a self-driving vehicle, computer vision augmented with other sensor data (i.e., lidar) usually leads to a detailed, high-resolution context, real-time 360-degree field of view. As this context changes, the underlying AI learning mechanism must decide when to intervene and how.
The second challenge occurs when an AI trained on data within a particular context gets deployed to a different context. Taking the self-driving car as an example, considering that the AI was trained in sunny California, would the same AI be able to drive safely on snowy roads in Norway during the winter? Likewise, if a driving AI was training on central European roads where road lines and signs are usually clearly visible, will the same AI work in a remote African area with only dirt roads and without road signs? A change of context usually entails re-evaluating the assumptions made during the initial training and thus requires a mechanism that tests whether the underlying assumptions are still present.
The third challenge adds to issues seen in the previous two by incorporating information from multiple disjointed contexts. While human cognition processes different senses simultaneously, computational perception relies on numerous separate data streams, each representing a different context. One can model an aggregation layer that merges multiple data streams into one single stream, as is the case with enhanced computer vision in self-driving cars. However, even with aggregation layers in place, in practice, there is more than one data stream to consider at any point in time. For example, the intra-day timeframe can be regarded as a relatively short-term context in stock trading. In contrast, the weekly, monthly, or even yearly timeframe provides a relatively long-term context. At any point in time, to make a decision the immediate short-term and the relative long-term context must be considered to ensure the proper action in the given context.
Data in any context changes over time, hence requiring constant updating. Next, a change of context may happen which precipitates a test of whether the assumption made during training remains valid in a context. Lastly, the need to handle multiple contexts emerges from the simple need to address either multiple timeframes, multiple ranges of distance, multiple sources of contextual data, or any combination thereof.
DeepCausality enables context-aware causality reasoning by combining contexts and causal structures. Also, DeepCausality enables the encoding of assumptions to streamline tests determining whether a model, a context, or both apply to an environment.
A context can be static or dynamic, depending on the situation. The context structure is defined beforehand for a static context, whereas for a dynamic context, the structure is generated dynamically at runtime. Regardless of the specific structure, DeepCausality uses a hypergraph to internally represent arbitrary complex contexts.
A context hypergraph consists of multiple contextoids, each storing relevant contextual information. The contextoid is the central structure that abstracts over data, space, and time, with each containing one unit of measurement. For example, a temporal context comprises of contextoids, each storing information of a unit of time that links to one or more other contextoids. Note that the structure of a temporal context in DeepCausality is a time hypergraph in which time information is stored as contextoids. A context may also define specific data that occurs at a certain time. The context defines a separate data set that contains all the data linked to the corresponding unit of time, as illustrated in the diagram below.
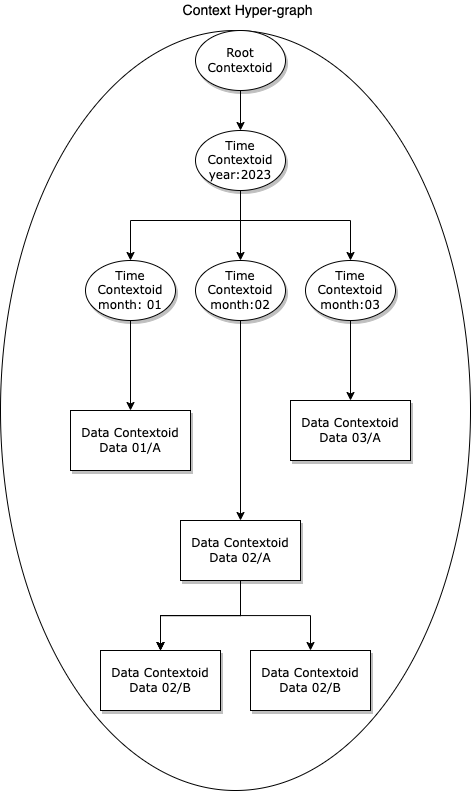
This separation is required because, at any point in time, more than one measurement may occur. For example, assuming two different sensors read in the same interval, say once a month in February. The month node links to two data readings to efficiently represent the time and data context.
Relations between data
Context can refer to either external data, say rain measurement, or internal, a maximum measurement from a data stream. Contextualizing a model relative to external data requires structuring that data in relation to space, time, or both. Contextualizing internal data, however, requires data pre-processing that structures it relative to space, time, or both. Indeed, no discernible difference exists to show whether a context has been constructed from internal or external data. Therefore, expressing relations between data sets or multiple data sources requires some form of pre-processing that is written into the context to make those relations explicit and accessible to a causal model.
The classic “Hello World” example in the financial industry is a crossing moving average, as shown in the diagram below (Courtesy of Investopedia). The candlestick bars represent the standard OHLC representation of a stock price. In the example, a long-term moving average is calculated over the previous 200 days to the closing price. Note that this rolling average is re-calculated every time a new day OHLC bar becomes available. Next, another short-term average is calculated for the previous 50 days. Lastly, the value of the 200 MA is compared to the value of the 50 MA to determine whether one has crossed over the other, as indicated by the golden cross in the diagram.
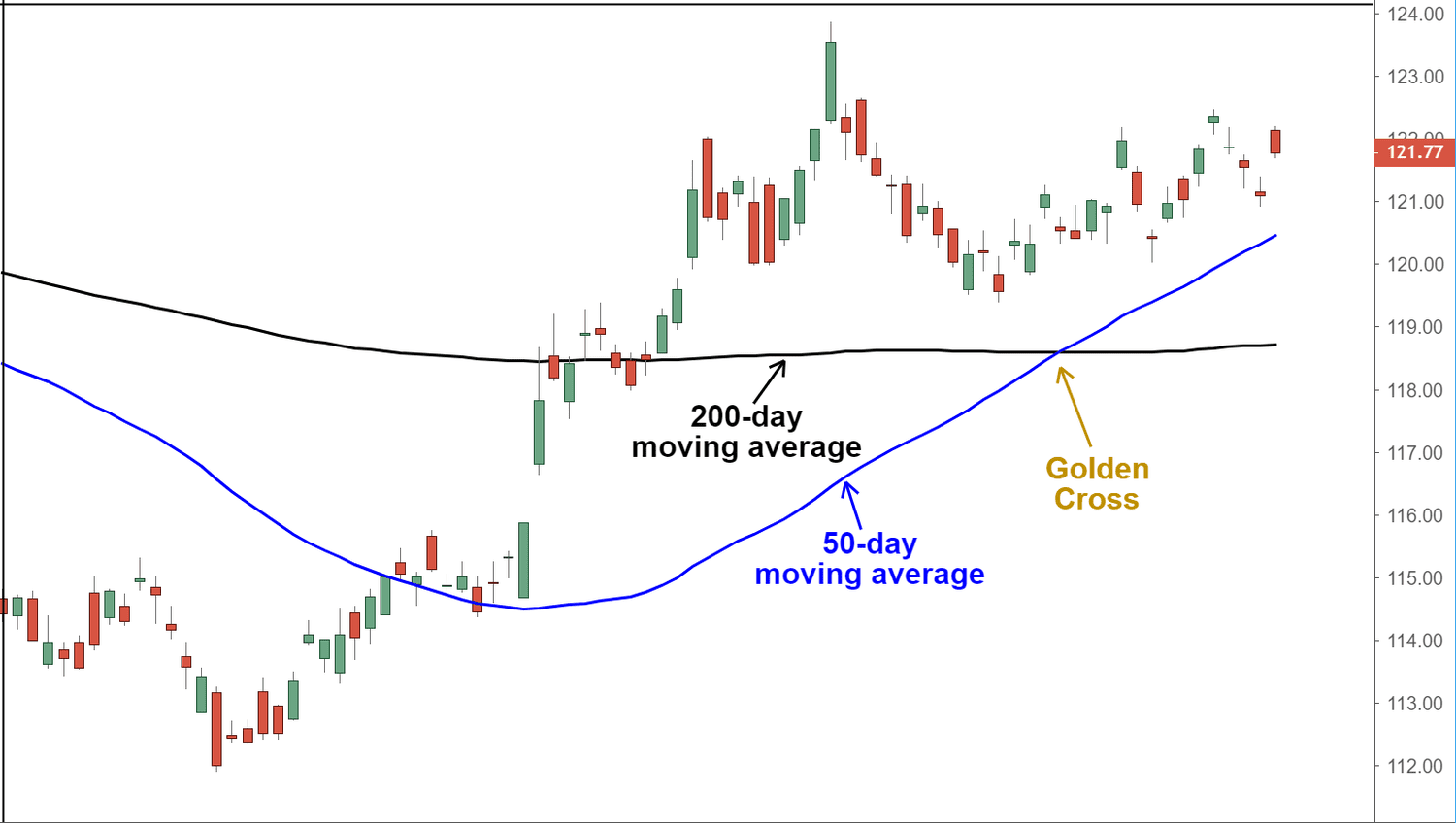
DeepCausality provides a straightforward solution for creating a context: for each day, add a new time node, calculate these values, store them in another node, and link the data node to the time node. The approach is scalable, meaning various average values can be added to days, months, quarters, or years by following the same pattern. The model can then easily access all current or previous values and perform various calculations. Therefore, arbitrary relations between a single data source or even between multiple data sources can be expressed efficiently and accessed from a model.
Conceptualization of time, space, and spacetime
It is often the case that data also has a space dimension and, in some cases, even a spacetime dimension. DeepCausality conceptualizes data, space, time, and spacetime as sub-structures of a contextoid. Specifically, a contextoid may contain one of the following sub-structures:
- Data – Contains data of type T
- Time – Contains one unit of time with type T
- Space – Contains one unit of space with type T
- SpaceTime – Contains one unit of spacetime with type T
Each provides a unique ID (remember, these are nodes in a hypergraph) and implements a corresponding protocol that defines a minimum set of methods.
Data
Data is the simplest structure since it only provides a unique ID and access to data of a type T.
Time
Time implements the temporal protocol that requires access to a TimeScale (a predefined Enum that encodes year, months, day, etc.) and a time unit of type T. In most cases, an unsigned integer would suffice as a time unit since, in Newtonian physics, time only moves forward and hence cannot have a negative value. However, the size of the integer may vary. An 8-bit integer would suffice when encoding months, whereas nanoseconds would require a 64-bit unsigned integer. More complex temporal structures are possible but require custom types.
Space
Space implements the spatial protocol that requires access to up to three coordinates (X,Y,Z) of type T. The reasoning is similar in that various spatial metrics may require different data types. Note that the space structure does not carry information about the encoded unit of space, so this needs to be added separately. Likewise, custom implementations are possible by re-implementing the spatial protocol.
SpaceTime
SpaceTime implements both the spatial and the temporal protocol, hence offering access to one unit of space at one unit of time. Specifically, one might not want to add a dedicated location node for every streamed coordinate. Instead, an area of operation is usually separated into several sectors, which would be a custom spatial type in a context. Within each sector, time nodes represent the data sampling intervals under which several spacetime nodes represent the actual time and location of the data measurement. Then, data nodes are added for each measurement taken at a certain time and space, which comes in handy when, for example, a drone streams multiple sensor data. In that case, the various data nodes are linked to a single spacetime node, implying that all measurements were taken simultaneously and at the same location.
DeepCausality provides two base implementations of these four structures:
- Non-adjustable
- Adjustable
Non-adjustable means that, after instantiation, the structure is immutable and cannot be changed anymore. There are scenarios where an immutable context comprising only immutable data is required, for example, in audited systems.
Adjustable means that the structure is mutable and can be changed after instantiation by implementing the adjustable protocol that provides two optional methods that need to be overwritten in order to activate them:
- Adjust
- Update
As a rule of thumb, adjust means a correction of a value, for example, for a shift in value. In contrast, update is conceptualized as the replacement of a value when, for instance, new data becomes available. The adjustment protocol does not enforce the implementation of its methods because each method has an empty default implementation, thus allowing for partial implementation based on actual requirements. Supposing that only the update method is needed, the implementation of the adjust method can be skipped.
The adjustable protocol aims to provide one uniform way of mutating values of any of the four structures embedded into a contextoid. Also, this mechanism is future-proof in three ways:
- Custom types that overwrite the adjust and update method remain compatible with context.
- In the case of adding a new category of context structure (say quaternion), the adjustable protocol ensures that the new structures are compatible with context.
- In the event of new requirements, say the need to delete context data, then the adjustable protocol can simply be extended with new custom signature types and implemented in custom types. If there is a demand for additional functionality, the official adjustable protocol might get an update.
DeepCausality does not provide any global update mechanism by default because it is preferable to allow users to be the best judge of how to modify a context and make use of the software.
For example, when feeding multiple data streams into a context, the update and model evaluation must happen in a fixed order to prevent consistency problems. However, there might be scenarios where partial updates and partial model evaluations might be needed even before the global context update has been completed. Therefore, DeepCausality only provides one uniform mechanism to update values in a context while leaving the global update strategy to the user.
Structural conceptualization of causation
DeepCausality uses the causaloid as its central structure, an idea borrowed from a novel causal concept pioneered by Lucien Hardy at the Perimeter Institute of Theoretical Physics. The causaloid encodes a causal relation as a causal function that maps input data to an output decision. It then determines whether, on the input data, the causal relation, encoded as a function, holds.
DeepCausality scales from simple to advanced use cases by offering a scalable causal data structure. Fundamentally, a causal data structure augments an existing data structure with abilities to conduct causal reasoning. DeepCausality provides a set of causal data structures that scale causal reasoning from simple to complex scenarios:
- Causal Array
- Causal HashMap
- Causal Vector
- Causal VecDeque
- Causaloid Graph
Transparent composability
The causaloid can be a singleton, a collection, or a graph. The causaloid graph, however, is a hypergraph with each node being a causaloid. This recursive structure means a sub-graph can be encapsulated as a causaloid, which then becomes a graph node. A HashMap of causes can also be encapsulated as a causaloid and embedded into the same graph.
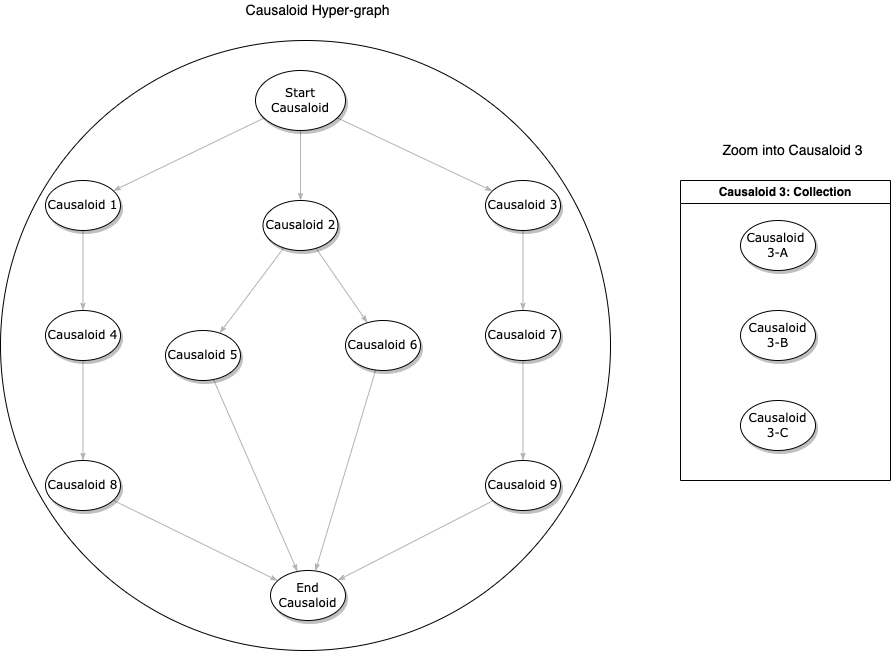
Then, the entire causaloid-graph can be analyzed in a variety of ways, for example:
- Reason over the entire graph
- Reason only over a specific causaloid
- Reason over all causaloids between a start and stop causaloid.
- Reason over the shortest path between two causaloids.
As long as causal mechanisms can be expressed as a hyper-graph, the graph is guaranteed to evaluate them. That means any combination of single cause, multi cause, or partial cause can be expressed across many layers. Also note that once activated, a causaloid stays activated until a different dataset evaluates it negatively, which will then deactivate the causaloid. Therefore, if parts of the dataset remain unchanged, the corresponding causaloids will remain active.
Contextualized causal reasoning is implemented by passing an immutable reference implicitly into the causal function. Note that this mechanism also allows us to contextualize certain causaloids while leaving others context-free if this is a desirable option. The diagram below shows this scenario in which specific causaloids use data from a context while other causaloids remain context-free.
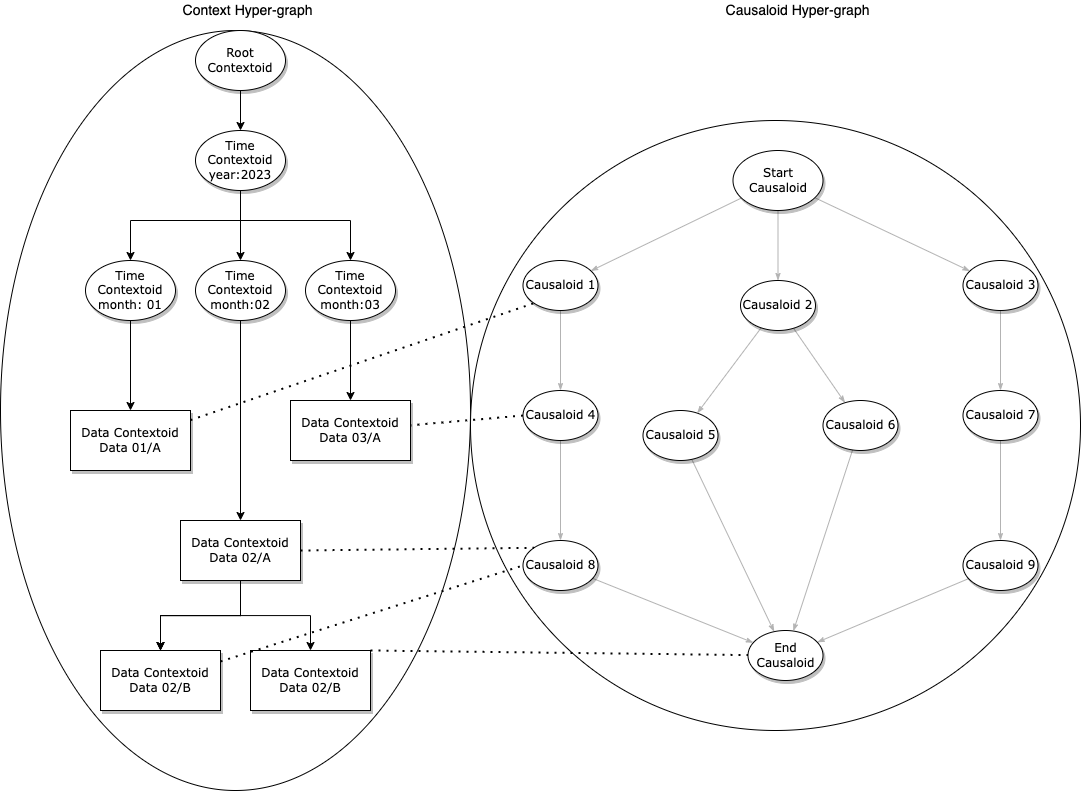
Due to the composition of different types of contextual data, comprehensive context data can be modeled. The diagram below, borrowed from a publication, illustrates such an example. A user node relates one user to another in a social layer. This can be represented in DeepCausality with a custom data type embedded into a context. One contextoid with user data for one user with edges that link to other users.
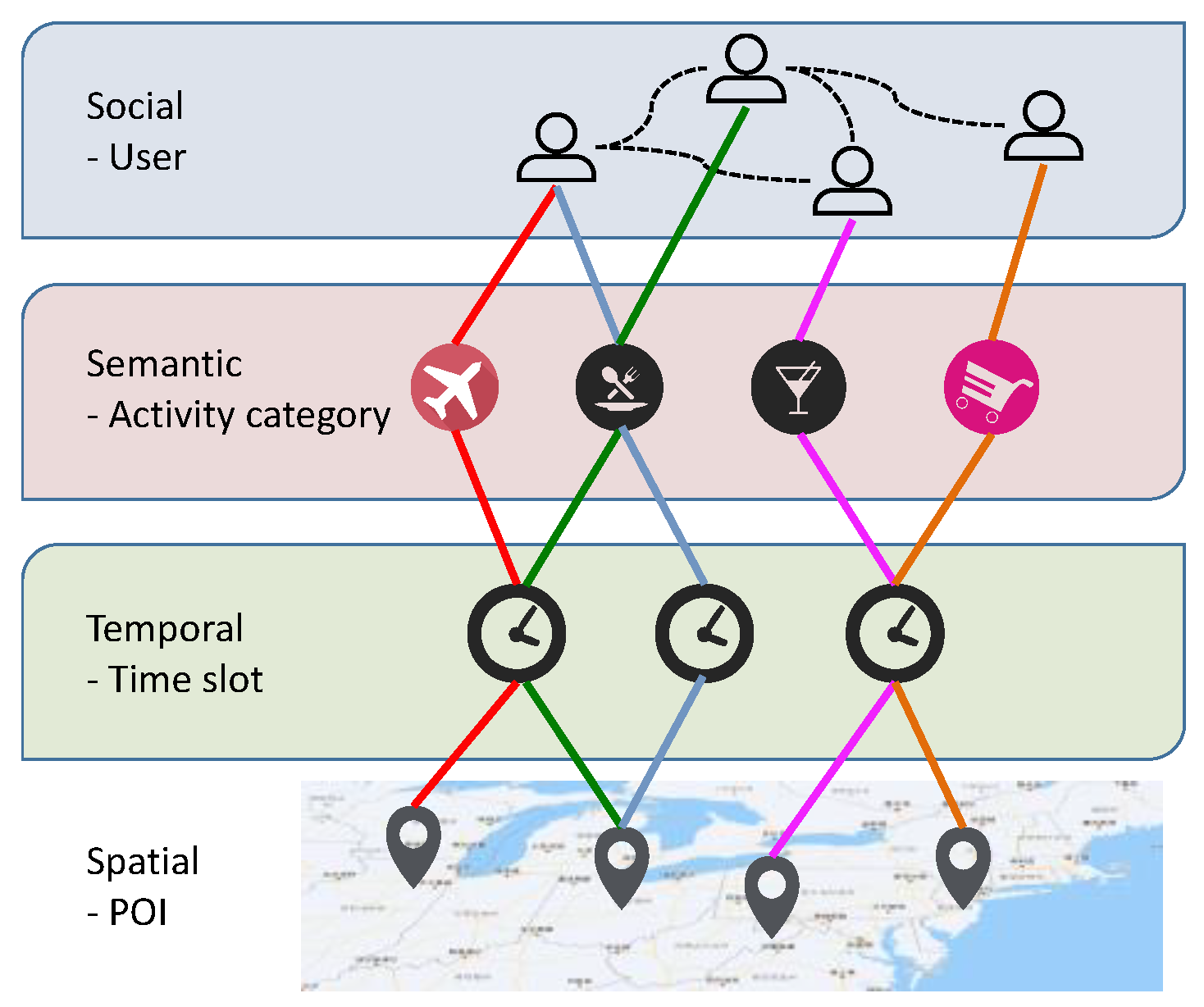
Likewise, activity categories linked to users can also be expressed with another custom data type embedded into a context. The edges represent links between users and activities. Temporal data like time slots can already be expressed with the default time type embedded into a contextoid.
Lastly, spatial data can use either a custom space type, or the default spacetime combined with a custom data time that further specifies a POI. Furthermore, “check-ins” of users at a specific POI at a particular time-slot can be expressed as a custom SpaceTime type that links locations to time-slots, activities, and users in one single type. DeepCausality already supports most of the functionality and also supports labeled edges, which help to traverse the context graph along certain edges while excluding others.
Reasoning performance for simple causality functions is a guaranteed sub-second for graphs below 10k nodes and microseconds for graphs below 1k nodes. However, graphs with well above 100k nodes may require a large amount of memory (> 10GB) because of the underlying sparse matrix representation.
Non-Euclidian data representation
DeepCausality has carefully chosen abstractions that preserve a high degree of flexibility. For example, the context abstracts over all four dimensions, and the causaloid abstracts over causal relations via its causal function. However, certain constraints remain in place; for example, the causal function still depends on data in a numerical format, which structurally binds data to be of Euclidean representation. Likewise, structures embedded into the context require its generic type to provide at least addition, subtraction, and multiplication, which technically constrains these structures to numerical categories. However, for many use cases in machine learning, this is appropriate and, thefore, made the default representation.
However, for scenarios that require non-Euclidean data representation, for example, neuro-symbolic reasoning, a custom context node, say symbol, can be added and embedded into a contextoid. That way, a neuro-symbolic context can be constructed using the same hypergraph capabilities to express neuro-symbolic structures within space, time, and spacetime.
The causaloid would require one modification to use only a causal function with a context but without a data argument. Also, the adjustable protocol will require some changes since the current implementation requires certain type constraints that conflict with non-Euclidean data representation. However, these constraints can be pushed downstream with only minimal effort. With all that in place, a custom protocol would enable neuro-symbolic reasoning, possibly within a mixed model containing Euclidean and non-Euclidean structures and reasoning.
Note that non-Euclidean representation and reasoning are all theoretical capabilities that have not been implemented. However, because of the flexible architecture of DeepCausality, these and similar capabilities can be added at a later stage with reasonable effort and then enable novel applications of advanced hybrid reasoning.
Next: Getting started
About
DeepCausality is a hyper-geometric computational causality library that enables fast and deterministic context-aware causal reasoning in Rust. Please give us a star on GitHub.